В своей работе «Математическая теория секретной связи» Клод Шеннон обобщил накопленный до него опыт разработки шифров.
Оказалось, что даже в сложных шифрах в качестве типичных компонентов можно выделить шифры замены, шифры перестановки или их сочетания.
14.1.Шифр замены
Наиболее известными и часто используемыми шифрами являются шифры замены . Они характеризуются тем, что отдельные части сообщения (буквы, слова, ...) заменяются на какие-либо другие буквы, числа, символы и т.д. При этом замена осуществляется так, чтобы потом по шифрованному сообщению можно было однозначно восстановить передаваемое сообщение.
При шифровании заменой (подстановкой ) символы шифруемого текста заменяются символами того же или другого алфавита с заранее установленным правилом замены. В шифре простой замены каждый символ исходного текста заменяется символами того же алфавита одинаково на всем протяжении текста.
Шифр замены является простейшим, наиболее популярным шифром. Примерами являются: шифр Цезаря , « цифирная азбука» Петра Великого и « пляшущие человечки» А. Конан-Дойля .
Шифр замены осуществляет преобразование замены букв или других «частей» открытого текста на аналогичные «части» шифрованного текста .
Увеличив алфавиты, т.е. объявив «части» буквами, можно любой шифр замены свести к замене букв.
Дадим математическое описание шифра замены .
Пусть: X – алфавит открытого текста, а Y - алфавит шифрованног о текста, состоящие из одинакового числа символов .
Пусть также: g: X Y – взаимнооднозначное отображение X в Y . Каждой буквех алфавита X сопоставляется однозначно определенная буква у алфавита Y , которую обозначаем символом g(х), причем разным буквам сопоставляются разные буквы .
Тогда шифр замены действует так: открытый текст x 1 x 2 ...x n преобразуется в шифрованный текст g (х 1 )g(x 2 )...g(x n ).
В криптографии рассматриваются 4 типа замены :
моноалфавитная;
гомофоническая;
полиалфавитная;
полиграммная.
Моноалфавитная замена
При данном методе каждому символу алфавита открытого текста ставится в соответствие один символ зашифрованного текста (из этого же алфавита).
Общая формула моноалфавитной замены выглядит следующим образом:
y i =(k 1 x i +k 2 )mod n,
Примером этого метода является шифр под названием Атбаш.
Правило шифрования состоит в замене i - ой буквы алфавита буквой с номером n= i + 1 , где n - число букв в алфавите. Пример для латинского алфавита выглядит так:
Исходный текст: abcdefghijklmnopqrstuvwxyz
Зашифрованный текст: ZYXWVUTSRQPONMLKJIHGFEDCBA
Гомофоническая замена
Особенность данного метода заключается в том, что одному символу открытого текста ставит в соответствие несколько символов шифртекста , что позволяет уйти от статистической взаимосвязи.
Примером данного шифра является книжный шифр - вид шифра, в котором каждый элемент открытого текста (каждая буква или слово) заменяется на указатель (например, номер страницы, строки и столбца) аналогичного элемента в дополнительном тексте-ключе.
Полиграммная замена
В полиграммных шифрах подстановки буквы открытого текста заменяются не по одной, а группами . Первое преимущество такого способа заключается в том, что распределение частот групп букв значительно более равномерное, чем отдельных символов. Во-вторых, для продуктивного частотного анализа требуется больший размер зашифрованного текста, так как число различных групп букв значительно больше, чем просто алфавит.
Полиалфавитные подстановки
Для повышения стойкости шифра используют так называемые полиалфавитные подстановки, которые для замены используют несколько алфавитов шифротекста.
Известно несколько разновидностей полиалфавитной подстановки, наиболее известными из которых являются:
одноконтурная (обыкновенная и монофоническая)
и многоконтурная.
При полиалфавитной одноконтурной обыкновенной подстановке для замены символов исходного текста используются несколько алфавитов, причем смена алфавитов осуществляется последовательно и циклически, т.е. первый символ заменяется соответствующим символом первого алфавита, второй – символом второго алфавита и т. д. до тех пор, пока не будут использованы все выбранные алфавиты. После этого использование алфавитов повторяется.
Сам процесс шифрования осуществляется следующим образом:
Под каждой буквой шифруемого теста записываются буквы ключа. Ключ при этом повторяется необходимое число раз;
Каждая буква шифруемого текста заменяется по подматрице буквами, находящимися на пересечении линий, соединяющих буквы шифруемого текста в первой строке подматрицы и находящихся под ними букв ключа;
Полученный текст может разбиваться на группы по несколько знаков.
Частным случаем рассмотренной полиалфавитной замены является так называемая монофоническая замена .
Шифрование осуществляется так же, как и при простой замене с той лишь разницей, что после шифрования каждого знака соответствующий ему столбец алфавитов циклически сдвигается вверх на одну позицию.
Полиалфавитная многоконтурная замена заключается в том, что для шифрования используется несколько наборов (контуров) алфавитов используемых циклически, причем каждый контур в общем случае имеет свой индивидуальный период применения. Этот период, исчисляется, как правило, количеством знаков, после зашифровки которых меняется контур алфавитов. Частным случаем многоконтурной полиалфавитной подстановки является замена по таблице Вижинера, если для шифрования используется несколько ключей, каждый из которых имеет свой период применения.
Шифрами замены называются такие шифры, преобразования из которых приводят к замене каждого символа открытого текста на другие символы – шифрообозначения, причем порядок следования шифрообозначений совпадает с порядком следования соответствующих им символов открытого сообщения.
Простейшим из шифров замены является одноалфавитная подстановка , называемая также шифром простой замены . Ключом такого шифра является взаимно однозначное отображение (подстановка ) F алфавита открытого текста (X ) в алфавит шифртекста (Y ): F : X ↔Y . Зафиксируем нумерацию символов в алфавитах X и Y : X = {x 1 , x 2 , … x n }, Y = {y 1 , y 2 , … y n }. Тогда отображение F фактически задается перестановкой p порядка n = |X | = |Y |: при шифровании символ x i открытого текста заменяется на символ y p ( i ) шифртекста. Эта перестановка может быть задана либо таблицей, либо с помощью формулы. При задании с помощью формулы значение p(i ) представляется в виде выражения, зависящего от i .
Типичным примером шифра замены является шифр Цезаря . Этот шифр реализует следующее преобразование текста, записанного с помощью латинского алфавита: каждая буква открытого текста заменяется буквой, стоящей на три позиции позже нее в алфавите (при этом алфавит считается записанным по кругу, то есть после буквы "z" идет буква "a"). Например, открытый текст "secret" будет преобразован в "vhfuhw". Ключ для шифра Цезаря можно задать в виде следующей таблицы (см. рис. 2.3). В первой строке записаны буквы открытого текста, во второй – соответствующие им буквы шифртекста.
Шифр Цезаря можно описать и в виде формулы. Для этого пронумеруем буквы латинского алфавита числами от 0 до 25: a = 0, b = 1, …, z = 25. Тогда правило замены можно описать следующим образом: буква с номером i i +3 (mod 26), где операция "mod 26" означает вычисление остатка от деления на 26.
Разумеется, возможен обобщенный вариант шифра Цезаря, при котором буква с номером i заменяется на букву с номером i +k (mod 26). В этом случае ключом шифра является число k .
Еще больше обобщив этот метод, мы придем к семейству аффинных шифров . Для алфавита из n символов {a 1 , a 2 , …, a n } аффинным шифром называется процедура, заменяющая входной символ a i на символ a j , где j = k ⋅i +l (mod n ). Для того чтобы имелась возможность расшифрования числа n и k должны быть взаимно простыми, то есть НОД(n , k ) = 1.
Шифры простой замены в настоящее время не используются, поскольку их стойкость невелика. Методы взлома таких шифров основаны на анализе частотности отдельных символов и их комбинаций. Дело в том, что в любом языке различные буквы и комбинации из двух, трех или большего количества букв имеют характерные частоты повторений в текстах. Например, в текстах на русском языке чаще всего встречается буква "О", затем, в порядке убывания частоты, идут буквы "Е" (считая, что "Е" и "Ё" – одна и та же буква), "А", "И", "Т" и т.д. Для английского языка аналогичная последовательность самых частых букв: "E", "T", "A", "I", "N". Самым частым символом в текстах является, однако, не буква, а символ пробела.
Ясно, что при использовании шифра простой замены частота повторений зашифрованных символов в шифртексте совпадает с частотой повторений соответствующих исходных символов в открытом тексте. Это позволяет достаточно легко вскрыть такой шифр. Более тонкие характеристики (учет сочетаемости различных букв) позволяют даже автоматизировать процесс взлома.
Для того чтобы увеличить стойкость шифров замены, применяют многоалфавитную подстановку, называемую также шифром сложной замены . Процедура шифрования для многоалфавитной замены включает набор подстановок {p 1 , p 2 ,…, p m } и функцию-распределительY (k ,i ), задающую последовательность применения подстановок p i . При шифровании i -го символа открытого текста применяется подстановка с номером Y (k ,i ), где k - ключ шифрования.
Частным случаем многоалфавитной замены является шифр Виженера. Формально этот шифр можно описать следующим образом. В качестве ключа шифрования выберем набор из m
целых чисел: k
= (k
1 , k
2 , …, k m
). Процедуру преобразования открытого текста t
= (t 1
, t 2
, …) в шифртекст c
= (c 1
, c 2
, …) построим на основе обобщенного шифра Цезаря: c
1 = t
1 + k
1 (mod 26),
c
2 = t
2 + k
2 (mod 26), и т.д. Когда будут использованы все m
компонент ключа k
, для шифрования (m
+1)-й буквы снова возьмем k
1 , и т.д. Фактически, в качестве ключа шифрования используется гамма шифра – бесконечная последовательность, образованная периодическим повторением исходного набора: k
1 ,k
2 ,…,k m
, k
1 ,k
2 ,…,k m
, k
1 ,k
2 ,…
Взломать шифр многоалфавитной замены немного сложнее, чем шифры простой замены, но тоже достаточно легко. Такой шифр на самом деле представляет собой одновременное применение m шифров простой замены (обобщенный шифр Цезаря), причем часть исходного текста, состоящая из букв t i , t m+i , t 2 m+i , … шифруются с использованием "ключа" k i (i =1, …,m ).
Если известен период гаммы (т.е. число m ), то к каждой такой части можно применить любой из методов взлома шифров простой замены. Если период гаммы не известен, то задача усложняется. Но и для этих случаев разработаны эффективные методы взлома. Эти методы позволяют с достаточной вероятностью определить период гаммы, после чего задача сводится к взлому шифра гаммирования с известным периодом.
Как было указано выше, основой для атак на шифры замены является анализ частот вхождений символов в шифртекст. Для того чтобы затруднить взлом шифра замены, можно попытаться скрыть частотные свойства исходного текста. Для этого надо, чтобы частоты появления разных символов в зашифрованном тексте совпадали. Такие шифры замены называются гомофоническими .
Простейшим вариантом гомофонического шифра является следующий. Предположим, что нам известны частоты вхождений символов в открытый текст. Пусть f i - частота появления i –го символа в открытом текста (i - номер буквы в алфавите). Каждой букве t i исходного алфавита (т.е. алфавита, с помощью которого записывается открытое сообщение) сопоставим подмножество F i , содержащее f i символов выходного алфавита (т.е. алфавита, с помощью которого записывается шифртекст), причем никакие два подмножества F i и F j не пересекаются. При шифровании будем заменять каждое вхождение символа t i на случайный символ из множества F i . Ясно, что средняя частота появления в шифртексте любого из символов выходного алфавита одинакова, что существенно затрудняет криптоанализ.
Шифры гаммирования
Формально гаммирование можно отнести к классу шифров сложной замены. Однако, благодаря удобству реализации и формального описания, шифры гаммирования широко используются, и обычно их выделяются в отдельный класс.
Суть метода гаммирования заключается в следующем. С помощью секретного ключа k генерируется последовательность символов
Эта последовательность называется гаммой шифра. При шифровании гамма накладывается на открытый текст ![]() , т.е. символы шифртекста получаются из соответствующих символов открытого текста и гаммы с помощью некоторой обратимой операции:
, т.е. символы шифртекста получаются из соответствующих символов открытого текста и гаммы с помощью некоторой обратимой операции: ![]()
В качестве обратимой операции обычно используется либо сложение по модулю количества букв в алфавите n : либо, при представлении символов открытого текста в виде двоичного кода, операция поразрядного суммирования по модулю два (XOR): .
Расшифрование осуществляется применением к символам шифртекста и гаммы обратной операции: ![]() , или (операция XOR является обратной к самой себе).
, или (операция XOR является обратной к самой себе).
Стойкость систем шифрования, основанных на гаммировании, зависит от характеристик гаммы – ее длины и равномерности распределения вероятностей появления знаков гаммы.
Наиболее стойким является гаммирование с бесконечной равновероятной случайной гаммой, т.е. процедура шифрования, удовлетворяющая следующим трем условиям, каждое из которых является необходимым:
1) все символы гаммы полностью случайны и появляются в гамме с равными вероятностями;
2) длина гаммы равна длине открытого текста или превышает ее;
3) каждый ключ (гамма) используется для шифрования только одного текста, а потом уничтожается.
Такой шифр не может быть взломан в принципе, то есть является абсолютно стойким. Однако абсолютно стойкие шифры очень не удобны в использовании, и поэтому почти не применяются на практике.
Обычно гамма либо получается периодическим повторением ключевой последовательности фиксированного размера, либо генерируется по некоторому правилу. Для генерации гаммы удобно использовать генераторы псевдослучайных чисел (ПСЧ). Наиболее известными генераторами ПСП являются линейный конгруэнтный генератор и генератор линейный рекуррентный последовательности.
Линейный конгруэнтный генератор задается рекуррентной формулой: g i = a ×g i – 1 + b (mod m ), где g i – i -й член последовательности псевдослучайных чисел; a , b , m и g 0 – ключевые параметры. Данная последовательность состоит из целых чисел от 0 до m – 1, и если элементы g i и g j совпадут, то последующие участки последовательности также совпадут: g i +1 = g j +1 , g i +2 = g j +2 , и т.д. Поэтому последовательность {g i } является периодической, и ее период не превышает m . Для того чтобы период последовательности псевдослучайных чисел, сгенерированной по указанной рекуррентной формуле, был максимальным (равным m), параметры данной формулы должны удовлетворять следующим условиям:
· b и m -взаимно простые числа;
· a – 1 делится на любой простой делитель числа m ;
· a – 1 кратно 4, если m кратно 4.
Линейная рекуррентная последовательность задается следующей формулой:
 , i =
0,1…,
, i =
0,1…,
где Å – операция вычисления суммы по модулю 2, – состояние j
-го бита последовательности, – коэффициент обратной связи, ![]() , коэффициенты
, коэффициенты ![]() .
.
Это соотношение определяет правило вычисления по известным значениям величин ![]() . Затем по известным значениям
. Затем по известным значениям ![]() находят и т.д. В результате по начальным значениям
находят и т.д. В результате по начальным значениям ![]() можно построить бесконечную последовательность, причем каждый ее последующий член определяется из n
предыдущих.
можно построить бесконечную последовательность, причем каждый ее последующий член определяется из n
предыдущих.
Последовательности такого вида легко реализуются программными или аппаратными средствами. Основу этой реализации составляет регистр сдвига с линейной обратной связью (РСЛОС).
РСЛОС представляет собой простое в реализации, недорогое устройство, способное формировать последовательности и обеспечить такие требования как:
· большой размер ансамбля последовательностей, формируемых на одной алгоритмической основе;
· оптимальность корреляционных функций в ансамбле;
· сбалансированность структуры;
· максимальность периода для данной длины регистра сдвига.
Обобщенная схема РСЛОС приведена на рис. 2.4.
Сдвиговый регистр представляет собой последовательность битов. Количество битов определяется длиной регистра. Если длина равна n битам, то регистр называется n -битовым регистром сдвига. Всякий раз, когда в выходную последовательность нужно извлечь бит, все биты регистра сдвига сдвигаются вправо на 1 позицию. Новый крайний левый бит является функцией всех остальных битов регистра. Выдвинутый из регистра бит является очередным элементом последовательности. Периодом регистра сдвига называется длина получаемой последовательности до начала ее повторения.
Обратная связь представляет собой просто операцию XOR над битами регистра, для которых значения коэффициентов обратной связи равно 1. Перечень этих битов называется отводной последовательностью .
Любой n -битовый РСЛОС может находиться в одном из 2 n –1 внутренних состояний. Это означает, что теоретически такой регистр может генерировать псевдослучайную последовательность с периодом 2 n –1 битов. (Число внутренних состояний и максимальный период равны 2 n –1, потому что заполнение РСЛОС нулями, приведет к тому, что сдвиговый регистр будет выдавать бесконечную последовательность нулей, что абсолютно бесполезно.) Только при определенных отводных последовательностях РСЛОС циклически пройдет через все 2 n –1 внутренних состояний, такие РСЛОС являются регистрами с максимальным периодом. Получившийся результат называется М – последовательностью .
Для того, чтобы конкретный n -битовый РСЛОС имел максимальный период 2 n –1, двоичный полином f (x ) = h n x n + h n – 1 x n – 1 + … + h 1 x + 1, образованный из отводной последовательности и константы 1, должен быть примитивным. Полином f (x ) степени n называется примитивным , если его нельзя представить в виде произведения двух полиномов с меньшими степенями (свойство неприводимости) и, если x является генератором всех ненулевых полиномов со степенями не выше n , умножение которых осуществляется по модулю f (x ).
В общем случае не существует эффективного способа генерировать примитивные полиномы данной степени. Проще всего выбирать полином случайным образом и проверять, не является ли он примитивным. Это чем-то похоже на проверку, не является ли простым случайно выбранное число. В настоящее время составлены таблицы примитивных полиномов, которыми можно воспользоваться при разработке конкретных РСЛОС.
В шифрах замены (или шифрах подстановки), в отличие от , элементы текста не меняют свою последовательность, а изменяются сами, т.е. происходит замена исходных букв на другие буквы или символы (один или несколько) по неким правилам.
На этой страничке описаны шифры, в которых замена происходит на буквы или цифры. Когда же замена происходит на какие-то другие не буквенно-цифровые символы, на комбинации символов или рисунки, это называют прямым .
Моноалфавитные шифры
В шифрах с моноалфавитной заменой каждая буква заменяется на одну и только одну другую букву/символ или группу букв/символов. Если в алфавите 33 буквы, значит есть 33 правила замены: на что менять А, на что менять Б и т.д.
Такие шифры довольно легко расшифровать даже без знания ключа. Делается это при помощи частотного анализа зашифрованного текста - надо посчитать, сколько раз каждая буква встречается в тексте, и затем поделить на общее число букв. Получившуюся частоту надо сравнить с эталонной. Самая частая буква для русского языка - это буква О, за ней идёт Е и т.д. Правда, работает частотный анализ на больших литературных текстах. Если текст маленький или очень специфический по используемым словам, то частотность букв будет отличаться от эталонной, и времени на разгадывание придётся потратить больше. Ниже приведена таблица частотности букв (то есть относительной частоты встречаемых в тексте букв) русского языка, рассчитанная на базе НКРЯ .
Использование метода частотного анализа для расшифровки шифрованных сообщений красиво описано во многих литературных произведениях, например, у Артура Конана Дойля в романе « » или у Эдгара По в « ».
Составить кодовую таблицу для шифра моноалфавитной замены легко, но запомнить её довольно сложно и при утере восстановить практически невозможно, поэтому обычно придумывают какие-то правила составления таких кодовых страниц. Ниже приведены самые известные из таких правил.
Случайный код
Как я уже писал выше, в общем случае для шифра замены надо придумать, какую букву на какую надо заменять. Самое простое - взять и случайным образом перемешать буквы алфавита, а потом их выписать под строчкой алфавита. Получится кодовая таблица. Например, вот такая:
Число вариантов таких таблиц для 33 букв русского языка = 33! ≈ 8.683317618811886*10 36 . С точки зрения шифрования коротких сообщений - это самый идеальный вариант: чтобы расшифровать, надо знать кодовую таблицу. Перебрать такое число вариантов невозможно, а если шифровать короткий текст, то и частотный анализ не применишь.
Но для использования в квестах такую кодовую таблицу надо как-то по-красивее преподнести. Разгадывающий должен для начала эту таблицу либо просто найти, либо разгадать некую словесно-буквенную загадку. Например, отгадать или решить .
Ключевое слово
Один из вариантов составления кодовой таблицы - использование ключевого слова. Записываем алфавит, под ним вначале записываем ключевое слово, состоящее из неповторяющихся букв, а затем выписываем оставшиеся буквы. Например, для слова «манускрипт» получим вот такую таблицу:
Как видим, начало таблицы перемешалось, а вот конец остался неперемешенным. Это потому, что самая «старшая» буква в слове «манускрипт» - буква «У», вот после неё и остался неперемешенный «хвост». Буквы в хвосте останутся незакодированными. Можно оставить и так (так как большая часть букв всё же закодирована), а можно взять слово, которое содержит в себе буквы А и Я, тогда перемешаются все буквы, и «хвоста» не будет.
Само же ключевое слово можно предварительно тоже загадать, например при помощи или . Например, вот так:

Разгадав арифметический ребус-рамку и сопоставив буквы и цифры зашифрованного слова, затем нужно будет получившееся слово вписать в кодовую таблицу вместо цифр, а оставшиеся буквы вписать по-порядку. Получится вот такая кодовая таблица:
Атбаш
Изначально шифр использовался для еврейского алфавита, отсюда и название. Слово атбаш (אתבש) составлено из букв «алеф», «тав», «бет» и «шин», то есть первой, последней, второй и предпоследней букв еврейского алфавита. Этим задаётся правило замены: алфавит выписывается по порядку, под ним он же выписывается задом наперёд. Тем самым первая буква кодируется в последнюю, вторая - в предпоследнюю и т.д.
Фраза «ВОЗЬМИ ЕГО В ЭКСЕПШН» превращается при помощи этого шифра в «ЭРЧГТЦ ЪЬР Э ВФНЪПЖС». Онлайн-калькулятор шифра Атбаш
ROT1
Этот шифр известен многим детям. Ключ прост: каждая буква заменяется на следующую за ней в алфавите. Так, A заменяется на Б, Б на В и т.д., а Я заменяется на А. «ROT1» значит «ROTate 1 letter forward through the alphabet» (англ. «поверните/сдвиньте алфавит на одну букву вперед»). Сообщение «Хрюклокотам хрюклокотамит по ночам» станет «Цсялмплпубн цсялмплпубнйу рп опшбн». ROT1 весело использовать, потому что его легко понять даже ребёнку, и легко применять для шифрования. Но его так же легко и расшифровать.
Шифр Цезаря
Шифр Цезаря - один из древнейших шифров. При шифровании каждая буква заменяется другой, отстоящей от неё в алфавите не на одну, а на большее число позиций. Шифр назван в честь римского императора Гая Юлия Цезаря, использовавшего его для секретной переписки. Он использовал сдвиг на три буквы (ROT3). Шифрование для русского алфавита многие предлагают делать с использованием такого сдвига:

Я всё же считаю, что в русском языке 33 буквы, поэтому предлагаю вот такую кодовую таблицу:
Интересно, что в этом варианте в алфавите замены читается фраза «где ёж?»:)
Но сдвиг ведь можно делать на произвольное число букв - от 1 до 33. Поэтому для удобства можно сделать диск, состоящий из двух колец, вращающихся относительно друг друга на одной оси, и написать на кольцах в секторах буквы алфавита. Тогда можно будет иметь под рукой ключ для кода Цезаря с любым смещением. А можно совместить на таком диске шифр Цезаря с атбашем, и получится что-то вроде этого:

Собственно, поэтому такие шифры и называются ROT - от английского слова «rotate» - «вращать».
ROT5
В этом варианте кодируются только цифры, остальной текст остаётся без изменений. Производится 5 замен, поэтому и ROT5: 0↔5, 1↔6, 2↔7, 3↔8, 4↔9.
ROT13
ROT13 - это вариация шифра Цезаря для латинского алфавита со сдвигом на 13 символов. Его часто применяют в интернете в англоязычных форумах как средство для сокрытия спойлеров, основных мыслей, решений загадок и оскорбительных материалов от случайного взгляда.

Латинский алфавит из 26 букв делится на две части. Вторая половина записывается под первой. При кодировании буквы из верхней половины заменяются на буквы из нижней половины и наоборот.
ROT18
Всё просто. ROT18 - это комбинация ROT5 и ROT13:)
ROT47
Существует более полный вариант этого шифра - ROT47. Вместо использования алфавитной последовательности A–Z, ROT47 использует больший набор символов, почти все отображаемые символы из первой половины ASCII -таблицы. При помощи этого шифра можно легко кодировать url, e-mail, и будет непонятно, что это именно url и e-mail:)
Например, ссылка на этот текст зашифруется вот так: 9EEAi^^?@K5C]CF^82>6D^BF6DE^4CJAE^4:A96C^K2>6?2nURC@Ecf. Только опытный разгадывальщик по повторяющимся в начале текста двойкам символов сможет додуматься, что 9EEAi^^ может означать HTTP:⁄⁄ .
Квадрат Полибия
Полибий - греческий историк, полководец и государственный деятель, живший в III веке до н.э. Он предложил оригинальный код простой замены, который стал известен как «квадрат Полибия» (англ. Polybius square) или шахматная доска Полибия. Данный вид кодирования изначально применялся для греческого алфавита, но затем был распространен на другие языки. Буквы алфавита вписываются в квадрат или подходящий прямоугольник. Если букв для квадрата больше, то их можно объединять в одной ячейке.

Такую таблицу можно использовать как в шифре Цезаря. Для шифрования на квадрате находим букву текста и вставляем в шифровку нижнюю от неё в том же столбце. Если буква в нижней строке, то берём верхнюю из того же столбца. Для кириллицы можно использовать таблицу РОТ11 (аналог шифра Цезаря со сдвигом на 11 символов):

Буквы первой строки кодируются в буквы второй, второй - в третью, а третьей - в первую.
Но лучше, конечно, использовать «фишку» квадрата Полибия - координаты букв:
Под каждой буквой кодируемого текста записываем в столбик две координаты (верхнюю и боковую). Получится две строки. Затем выписываем эти две строки в одну строку, разбиваем её на пары цифр и используя эти пары как координаты, вновь кодируем по квадрату Полибия.
Можно усложнить. Исходные координаты выписываем в строку без разбиений на пары, сдвигаем на нечётное количество шагов, разбиваем полученное на пары и вновь кодируем.
Квадрат Полибия можно создавать и с использованием кодового слова. Сначала в таблицу вписывается кодовое слово, затем остальные буквы. Кодовое слово при этом не должно содержать повторяющихся букв.
Вариант шифра Полибия используют в тюрьмах, выстукивая координаты букв - сначала номер строки, потом номер буквы в строке.
Стихотворный шифр
Этот метод шифрования похож на шифр Полибия, только в качестве ключа используется не алфавит, а стихотворение, которое вписывается построчно в квадрат заданного размера (например, 10×10). Если строка не входит, то её «хвост» обрезается. Далее полученный квадрат используется для кодирования текста побуквенно двумя координатами, как в квадрате Полибия. Например, берём хороший стих «Бородино» Лермонтова и заполняем таблицу. Замечаем, что букв Ё, Й, Х, Ш, Щ, Ъ, Э в таблице нет, а значит и зашифровать их мы не сможем. Буквы, конечно, редкие и могут не понадобиться. Но если они всё же будут нужны, придётся выбирать другой стих, в котором есть все буквы.

РУС/LAT
Наверное, самый часто встречающийся шифр:) Если пытаться писать по-русски, забыв переключиться на русскую раскладку, то получится что-то типа этого: Tckb gsnfnmcz gbcfnm gj-heccrb? pf,sd gthtrk.xbnmcz yf heccre. hfcrkflre? nj gjkexbncz xnj-nj nbgf "njuj^ Ну чем не шифр? Самый что ни на есть шифр замены. В качестве кодовой таблицы выступает клавиатура.

Таблица перекодировки выглядит вот так:

Литорея
Литорея (от лат. littera - буква) - тайнописание, род шифрованного письма, употреблявшегося в древнерусской рукописной литературе. Известна литорея двух родов: простая и мудрая. Простая, иначе называемая тарабарской грамотой, заключается в следующем. Если «е» и «ё» считать за одну букву, то в русском алфавите остаётся тридцать две буквы, которые можно записать в два ряда - по шестнадцать букв в каждом:
Получится русский аналог шифра ROT13 - РОТ16 :) При шифровке верхнюю букву меняют на нижнюю, а нижнюю - на верхнюю. Ещё более простой вариант литореи - оставляют только двадцать согласных букв:

Получается шифр РОТ10 . При шифровании меняют только согласные, а гласные и остальные, не попавшие в таблицу, оставляют как есть. Получается что-то типа «словарь → лсошамь» и т.п.
Мудрая литорея предполагает более сложные правила подстановки. В разных дошедших до нас вариантах используются подстановки целых групп букв, а также числовые комбинации: каждой согласной букве ставится в соответствие число, а потом совершаются арифметические действия над получившейся последовательностью чисел.
Шифрование биграммами
Шифр Плейфера
Шифр Плейфера - ручная симметричная техника шифрования, в которой впервые использована замена биграмм. Изобретена в 1854 году Чарльзом Уитстоном. Шифр предусматривает шифрование пар символов (биграмм), вместо одиночных символов, как в шифре подстановки и в более сложных системах шифрования Виженера. Таким образом, шифр Плейфера более устойчив к взлому по сравнению с шифром простой замены, так как затрудняется частотный анализ.
Шифр Плейфера использует таблицу 5х5 (для латинского алфавита, для русского алфавита необходимо увеличить размер таблицы до 6х6), содержащую ключевое слово или фразу. Для создания таблицы и использования шифра достаточно запомнить ключевое слово и четыре простых правила. Чтобы составить ключевую таблицу, в первую очередь нужно заполнить пустые ячейки таблицы буквами ключевого слова (не записывая повторяющиеся символы), потом заполнить оставшиеся ячейки таблицы символами алфавита, не встречающимися в ключевом слове, по порядку (в английских текстах обычно опускается символ «Q», чтобы уменьшить алфавит, в других версиях «I» и «J» объединяются в одну ячейку). Ключевое слово и последующие буквы алфавита можно вносить в таблицу построчно слева-направо, бустрофедоном или по спирали из левого верхнего угла к центру. Ключевое слово, дополненное алфавитом, составляет матрицу 5х5 и является ключом шифра.
Для того, чтобы зашифровать сообщение, необходимо разбить его на биграммы (группы из двух символов), например «Hello World» становится «HE LL OW OR LD», и отыскать эти биграммы в таблице. Два символа биграммы соответствуют углам прямоугольника в ключевой таблице. Определяем положения углов этого прямоугольника относительно друг друга. Затем руководствуясь следующими 4 правилами зашифровываем пары символов исходного текста:
1) Если два символа биграммы совпадают, добавляем после первого символа «Х», зашифровываем новую пару символов и продолжаем. В некоторых вариантах шифра Плейфера вместо «Х» используется «Q».
2) Если символы биграммы исходного текста встречаются в одной строке, то эти символы замещаются на символы, расположенные в ближайших столбцах справа от соответствующих символов. Если символ является последним в строке, то он заменяется на первый символ этой же строки.
3) Если символы биграммы исходного текста встречаются в одном столбце, то они преобразуются в символы того же столбца, находящимися непосредственно под ними. Если символ является нижним в столбце, то он заменяется на первый символ этого же столбца.
4) Если символы биграммы исходного текста находятся в разных столбцах и разных строках, то они заменяются на символы, находящиеся в тех же строках, но соответствующие другим углам прямоугольника.
Для расшифровки необходимо использовать инверсию этих четырёх правил, откидывая символы «Х» (или «Q») , если они не несут смысла в исходном сообщении.
Рассмотрим пример составления шифра. Используем ключ «Playfair example», тогда матрица примет вид:

Зашифруем сообщение «Hide the gold in the tree stump». Разбиваем его на пары, не забывая про правило . Получаем: «HI DE TH EG OL DI NT HE TR EX ES TU MP». Далее применяем правила -:
1. Биграмма HI формирует прямоугольник, заменяем её на BM.
2. Биграмма DE расположена в одном столбце, заменяем её на ND.
3. Биграмма TH формирует прямоугольник, заменяем её на ZB.
4. Биграмма EG формирует прямоугольник, заменяем её на XD.
5. Биграмма OL формирует прямоугольник, заменяем её на KY.
6. Биграмма DI формирует прямоугольник, заменяем её на BE.
7. Биграмма NT формирует прямоугольник, заменяем её на JV.
8. Биграмма HE формирует прямоугольник, заменяем её на DM.
9. Биграмма TR формирует прямоугольник, заменяем её на UI.
10. Биграмма EX находится в одной строке, заменяем её на XM.
11. Биграмма ES формирует прямоугольник, заменяем её на MN.
12. Биграмма TU находится в одной строке, заменяем её на UV.
13. Биграмма MP формирует прямоугольник, заменяем её на IF.
Получаем зашифрованный текст «BM ND ZB XD KY BE JV DM UI XM MN UV IF». Таким образом сообщение «Hide the gold in the tree stump» преобразуется в «BMNDZBXDKYBEJVDMUIXMMNUVIF».
Двойной квадрат Уитстона
Чарльз Уитстон разработал не только шифр Плейфера, но и другой метод шифрования биграммами, который называют «двойным квадратом». Шифр использует сразу две таблицы, размещенные по одной горизонтали, а шифрование идет биграммами, как в шифре Плейфера.
Имеется две таблицы со случайно расположенными в них русскими алфавитами.

Перед шифрованием исходное сообщение разбивают на биграммы. Каждая биграмма шифруется отдельно. Первую букву биграммы находят в левой таблице, а вторую букву - в правой таблице. Затем мысленно строят прямоугольник так, чтобы буквы биграммы лежали в его противоположных вершинах. Другие две вершины этого прямоугольника дают буквы биграммы шифртекста. Предположим, что шифруется биграмма исходного текста ИЛ. Буква И находится в столбце 1 и строке 2 левой таблицы. Буква Л находится в столбце 5 и строке 4 правой таблицы. Это означает, что прямоугольник образован строками 2 и 4, а также столбцами 1 левой таблицы и 5 правой таблицы. Следовательно, в биграмму шифртекста входят буква О, расположенная в столбце 5 и строке 2 правой таблицы, и буква В, расположенная в столбце 1 и строке 4 левой таблицы, т.е. получаем биграмму шифртекста ОВ.
Если обе буквы биграммы сообщения лежат в одной строке, то и буквы шифртекста берут из этой же строки. Первую букву биграммы шифртекста берут из левой таблицы в столбце, соответствующем второй букве биграммы сообщения. Вторая же буква биграммы шифртекста берется из правой таблицы в столбце, соответствующем первой букве биграммы сообщения. Поэтому биграмма сообщения ТО превращается в биграмму шифртекста ЖБ. Аналогичным образом шифруются все биграммы сообщения:
Сообщение ПР ИЛ ЕТ АЮ _Ш ЕС ТО ГО
Шифртекст ПЕ ОВ ЩН ФМ ЕШ РФ БЖ ДЦ
Шифрование методом «двойного квадрата» дает весьма устойчивый к вскрытию и простой в применении шифр. Взламывание шифртекста «двойного квадрата» требует больших усилий, при этом длина сообщения должна быть не менее тридцати строк, а без компьютера вообще не реально.
Полиалфавитные шифры
Шифр Виженера
Естественным развитием шифра Цезаря стал шифр Виженера. В отличие от моноалфавитных это уже полиалфавитный шифр. Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига. Для зашифровывания может использоваться таблица алфавитов, называемая «tabula recta» или «квадрат (таблица) Виженера». На каждом этапе шифрования используются различные алфавиты, выбираемые в зависимости от буквы ключевого слова.
Для латиницы таблица Виженера может выглядеть вот так:

Для русского алфавита вот так:

Легко заметить, что строки этой таблицы - это ROT-шифры с последовательно увеличивающимся сдвигом.
Шифруют так: под строкой с исходным текстом во вторую строку циклически записывают ключевое слово до тех пор, пока не заполнится вся строка. У каждой буквы исходного текста снизу имеем свою букву ключа. Далее в таблице находим кодируемую букву текста в верхней строке, а букву кодового слова слева. На пересечении столбца с исходной буквой и строки с кодовой буквой будет находиться искомая шифрованная буква текста.
Важным эффектом, достигаемым при использовании полиалфавитного шифра типа шифра Виженера, является маскировка частот появления тех или иных букв в тексте, чего лишены шифры простой замены. Поэтому к такому шифру применить частотный анализ уже не получится.
Для шифрования шифром Виженера можно воспользоваться Онлайн-калькулятором шифра Виженера . Для различных вариантов шифра Виженера со сдвигом вправо или влево, а также с заменой букв на числа можно использовать приведённые ниже таблицы:


Шифр Гронсвельда
Книжный шифр
Если же в качестве ключа использовать целую книгу (например, словарь), то можно зашифровывать не отдельные буквы, а целые слова и даже фразы. Тогда координатами слова будут номер страницы, номер строки и номер слова в строке. На каждое слово получится три числа. Можно также использовать внутреннюю нотацию книги - главы, абзацы и т.п. Например, в качестве кодовой книги удобно использовать Библию, ведь там есть четкое разделение на главы, и каждый стих имеет свою маркировку, что позволяет легко найти нужную строку текста. Правда, в Библии нет современных слов типа «компьютер» и «интернет», поэтому для современных фраз лучше, конечно, использовать энциклопедический или толковый словарь.
Это были шифры замены, в которых буквы заменяются на другие. А ещё бывают , в которых буквы не заменяются, а перемешиваются между собой.
Шифры замены
Шифры замены, или подстановки, являются самыми древними. В криптографии рассматриваются 4 типа замены: моноалфавитная, гомофоническая, полиалфавитная и полиграммная. При моноалфавитной замене каждой букве алфавита открытого текста ставится в соответствие одна буква шифртекста из этого же алфавита. Приведем пример:
| а | б | в | г | д | е | ж | З |
| ф | ы | в | а | п | р | о | Л |
Тогда слово "багаж" будет заменено на слово "ыфафо". При расшифровании производится обратная операция.
Общая формула моноалфавитной замены выглядит следующим образом:
y i =k 1 x i +k 2 (mod n),
где y i – i-й символ алфавита; k 1 и k 2 – константы; x i – i-й символ открытого текста (номер буквы в алфавите); n – длина используемого алфавита.
Шифр, задаваемый формулой
y i =x i +k i (mod n),
где k i – i-я буква ключа, в качестве которого используется слово или фраза, называется шифром Вижинера .
Пример 2. Открытый текст: «ЗАМЕНА». Подстановка задана следующим образом:
| З | А | М | Е | Н | А |
| К | Л | Ю | Ч | К | Л |
y 1 = 8 + 11(mod 33) = 19 Т; y 2 =1 + 12(mod 33) = 13 М;
y 3 =13 + 31(mod ЗЗ) = 11 K; y 4 = 6 + 24(mod 33) = 30 Э;
y 5 = 14+ 11(mod 33) = 25 Щ; y 6 = 1 + 12(mod 33) = 13 М.
Шифртекст: «ТМКЭШМ».
Шифры Бофора используют формулы:
у i = k i – x i (mod n) и у i =x i – k i (mod n).
Основным недостатком является то, что статистические свойства открытого текста (частоты повторения букв) сохраняются и в шифртексте. Формальный подход к дешифрованию основан на использовании средней частоты появления букв в текстах. Впервые похожий метод был предложен в конце 15-го века (итальянский математик Леон Баттиста Альберти) и использовал свойство неравномерности встречаемости разных букв алфавита. Позднее были определены средние частоты использования букв языка в текстах:
Частота бyквосочетаний в английском языке:
TH, HE, IN, AN, EN, ER, OR, ES, ON, RE, AT, EA, ST, TI, ED, ND, NT, RR, LL, SS, MM.
QUI, ING, ION, ARE, TIO, ONE, ANT, MENT, TION, SION.
Частота бyквосочетаний в рyсском языке:
CТ, HО, ЕH, ТО, HА, ОВ, HИ, РА, ВО, КО, ОИ, ИИ, ИЕ, ЕИ, ОЕ, ИЯ, HH, CC.
CТО, ЕHО, HОВ, ТОВ, ОВО, HАЛ, РАЛ, HИC.
Кроме частоты появления букв, могут быть использованы другие обстоятельства, помогающие раскрыть сообщение. Например, может быть известна разбивка на слова и расставлены знаки препинания. Рассматривая сравнительно небольшое число возможных вариантов замены для предлогов и союзов, можно попытаться определить часть ключа. Использоваться может и то, какие буквы могут удвоены. Для искажения статистических свойств шифртекста применяются различные модификации.
Гомофоническая замена одному символу открытого текста ставит всоответствие несколько символов шифртекста.
Пример 3. Открытый текст: «ЗАМЕНА». Подстановка задана следующей таблицей:
Шифртекст: «76 17 32 97 55 31» .
Таким образом, при гомофонической замене каждая буква открытого текста заменяется по очереди цифрами соответствующего столбца.
Полиграммная замена формируется из одного алфавита с помощью специальных правил. В качестве примера рассмотрим шифр Плэйфера . В этом шифре алфавит располагается в матрице. Открытый текст разбивается на пары символов x i ,x i+1 . , икаждая пара заменяется на пару символов из матрицы следующим образом:
· если символы находятся в одной строке, то каждый из символов пары заменяется на стоящий правее его (за последним символом в строке следует первый);
· если символы находятся в одном столбце, то каждый символ пары заменяется на символ, расположенный ниже его в столбце (за последним нижним символом следует верхний);
· если символы пары находятся в разных строках и столбцах, то они считаются противоположными углами прямоугольника. Символ, находящийся в левом углу, заменяется на символ, стоящий в другом левом углу; замена символа, находящегося в правом углу, осуществляется аналогично;
· если в открытом тексте встречаются два одинаковых символа подряд, то перед шифрованием между ними вставляется специальный символ (например тире).
Пример 4. Открытый текст: «ШИФР ПЛЭЙФЕРА». Матрица алфавита представлена в следующей таблице. Шифртекст: «РДЫИ,– СТ – И.ХЧС».
| А | Ж | Б | М | Ц | В |
| Ч | Г | Н | Ш | Д | О |
| Е | Щ | , | Х | У | П |
| . | З | Ъ | Р | И | Й |
| С | Ь | К | Э | Т | Л |
| Ю | Я | _ | Ы | Ф | - |
При рассмотрении этих видов шифров становится очевидным, что чем больше длина ключа (например в шифре Вижинера), тем лучше шифр. Улучшения свойств шифртекста можно достигнуть при использовании шифров с автоключом.
Шифр, в котором сам открытый текст или получающаяся криптограмма используются в качестве ключа, называется шифром с автоключом . Шифрование в этом случае начинается с ключа, называемого первичным, и продолжается с помощью открытого текста или криптограммы, смещенной на длину первичного ключа.
Пример 5. Открытый текст: «ШИФРОВАНИЕ ЗАМЕНОЙ». Первичный ключ: «КЛЮЧ». Схема шифрования с автоключом при использовании открытого текста представлена в следующей таблице:
| Ш | И | Ф | Р | О | В | А | Н | И | Е | З | А | М | Е | Н | О | Й | |
| К | Л | Ю | Ч | Ш | И | Ф | Р | О | В | А | Н | И | Е | З | А | М | |
| В | Ф | Т | З | Ж | Л | Х | Ю | Ч | И | А | Х | Й | Т | Е | Х | П | Ц |
Схема шифрования с автоключом при использовании криптограммы представлена в следующей таблице:
| Ш | И | Ф | Р | О | В | А | Н | И | Е | З | А | М | Е | Н | О | Й | |
| К | Л | Ю | Ч | В | Ф | Т | З | С | Ч | У | Х | Ъ | Э | У | Э | Ы | Й |
| В | Ф | Т | З | С | Ч | У | Х | Ъ | Э | У | Э | Ы | Й | Щ | К | Й | У |
Для повышения стойкости шифра используют так называемые полиалфавитные подстановки , которые для замены используют несколько алфавитов шифротекста. Пусть имеется k алфавитов. Тогда открытый текст
X= x 1 x 2 ...x k x k +1 ...x 2 k x 2 k+1 ...
заменяется шифротекстом
У =f 1 (x 1)f 2 (x 2)...f k (x k)f 1 (x k+1)...f k (x 2k)f 1 (x 2k+1)...,
где f i (x j) означает символ шифртекста алфавита i для символа открытого текста x j .
Пример 6. Открытый текст: «ЗАМЕНА», k = 3. Подстановка задана таблицей из примера 3. Шифртекст: «76 31 61 97 84 48».
Известно несколько разновидностей полиалфавитной подстановки, наиболее известными из которых являются одноконтурная (обыкновенная и монофоническая) и многоконтурная.
При полиалфавитной одноконтурной обыкновенной подстановке для замены символов исходного текста используются несколько алфавитов, причем смена алфавитов осуществляется последовательно и циклически, т.е. первый символ заменяется соответствующим символом первого алфавита, второй – символом второго алфавита и т. д. до тех пор, пока не будут использованы все выбранные алфавиты. После этого использование алфавитов повторяется.
В качестве примера рассмотрим шифрование с помощью таблицы Вижинера . Таблица Вижинера представляет собой квадратную матрицу с n 2 элементами, где n – число символов используемого алфавита. Ниже показана таблица Вижинера для русского языка. Каждая строка получена циклическим сдвигом алфавита на символ. Для шифрования выбирается буквенный ключ, в соответствии с которым формируется рабочая матрица шифрования. Осуществляется это следующим образом. Из полной таблицы выбирается первая строка и те строки, первые буквы которых соответствуют буквам ключа. Первой размещается первая строка, а под нею – строки, соответствующие буквам ключа в порядке следования этих букв в ключе.
| а | б | в | г | д | е | ж | з | . | ь | ъ | ы | э | ю | я |
| б | в | г | д | е | ж | з | и | . | ъ | ы | э | ю | я | а |
| в | г | д | е | ж | з | и | й | . | ы | э | ю | я | а | б |
| .. | .. | |||||||||||||
| я | а | б | в | г | д | е | ж | . | щ | ь | ъ | ы | э | ю |
Сам процесс шифрования осуществляется следующим образом:
1. под каждой буквой шифруемого теста записываются буквы ключа. Ключ при этом повторяется необходимое число раз;
2. каждая буква шифруемого текста заменяется по подматрице буквами, находящимися на пересечении линий, соединяющих буквы шифруемого текста в первой строке подматрицы и находящихся под ними букв ключа;
3. полученный текст может разбиваться на группы по несколько знаков.
Исследования показали, что при использовании такого метода статистические характеристики исходного текста практически не проявляются в зашифрованном сообщении. Нетрудновидеть, что замена по таблице Вижинера эквивалентна простой замене с циклическим изменением алфавита, т. е. здесь мы имеем полиалфавитную подстановку, причем число используемых алфавитов определяется числом букв в слове-ключе. Поэтому стойкость такой замены определяется произведением стойкости прямой замены на число используемых алфавитов, т. е. на число букв в ключе.
Расшифрование текста производится в следующей последовательности:
1. над буквами зашифрованного текста последовательно надписываются буквы ключа, причем ключ повторяется необходимое число раз;
2. в строке подматрицы Вижинера, соответствующей букве ключа отыскивается буква, соответствующая знаку зашифрованного текста. Находящаяся под ней буква первой строки подматрицы и будет буквой исходного текста;
3. полученный текст группируется в слова по смыслу.
Нетрудно видеть, что процедуры как прямого, так и обратного преобразований являются строго формальными, что позволяет реализовать их алгоритмически. Более того, обе процедуры легко реализуются по одному и тому же алгоритму.
Одним из недостатков шифрования по таблице Вижинера является то, что при небольшой длине ключа надежность шифрования остается невысокой, а формирование длинных ключей сопряжено с трудностями. Нецелесообразно выбирать ключ с повторяющимися буквами, так как при этом стойкость шифра не возрастает.
С целью повышения стойкости шифрования можно использовать усовершенствованные варианты таблицы Вижинера. Приведем некоторые из них:
1) во всех (кроме первой) строках таблицы буквы располагаются в произвольном порядке;
2) в качестве ключа используются случайные последовательности чисел. Из таблицы Вижинера выбираются десять произвольных строк, которые кодируются натуральными числами от 0 до 10. Эти строки используются в соответствии с чередованием цифр в выбранном ключе.
Частным случаем рассмотренной полиалфавитной замены является так называемая монофоническая замена. Особенность этого метода состоит в том, что количество и состав алфавитов выбираются таким образом, чтобы частоты появления всех символов в зашифрованном тексте были одинаковыми. При таком положении затрудняется криптоанализ зашифрованного текста с помощью его статистической обработки. Выравнивание частот появления символов достигается за счет того, что для часто встречающихся символов исходного текста предусматривается использование большего числа заменяющих элементов, чем для редко встречающихся. Шифрование осуществляется также, как и при простой замене (т. е. по шифрующему алфавиту № 1) с той лишь разницей, что после шифрования каждого знака соответствующий ему столбец алфавитов циклически сдвигается вверх на одну позицию. Таким образом, столбцы алфавита как бы образуют независимые друг от друга кольца, поворачиваемые вверх на один знак каждый раз после шифрования соответствующего знака. При увеличении объема текста частоты появления символов будут еще более выравниваться.
Полиалфавитная многоконтурная замена заключается в том, что для шифрования используется несколько наборов (контуров) алфавитов используемых циклически, причем каждый контур в общем случае имеет свой индивидуальный период применения. Этот период, исчисляется, как правило, количеством знаков, после зашифровки которых меняется контур алфавитов. Частным случаем многоконтурной полиалфавитной подстановки является замена по таблице Вижинера, если для шифрования используется несколько ключей, каждый из которых имеет свой период применения.
Общая модель шифрования подстановкой может быть представлена в следующем виде:
t i ш = t i о + mod(k -1),
где t i ш – символ зашифрованного текста; t i о – символ исходного текста; – целое число в диапазоне 0 – (k -1); k – число символов используемого алфавита.
Поскольку шифров в мире насчитывается огромное количество, то рассмотреть все шифры невозможно не только в рамках данной статьи, но и целого сайта. Поэтому рассмотрим наиболее примитивные системы шифрации, их применение, а так же алгоритмы расшифровки. Целью своей статьи я ставлю максимально доступно объяснить широкому кругу пользователей принципов шифровки \ дешифровки, а так же научить примитивным шифрам.
Еще в школе я пользовался примитивным шифром, о котором мне поведали более старшие товарищи. Рассмотрим примитивный шифр «Шифр с заменой букв цифрами и обратно».
Нарисуем таблицу, которая изображена на рисунке 1. Цифры располагаем по порядку, начиная с единицы, заканчивая нулем по горизонтали. Ниже под цифрами подставляем произвольные буквы или символы.
Рис. 1 Ключ к шифру с заменой букв и обратно.
Теперь обратимся к таблице 2, где алфавиту присвоена нумерация.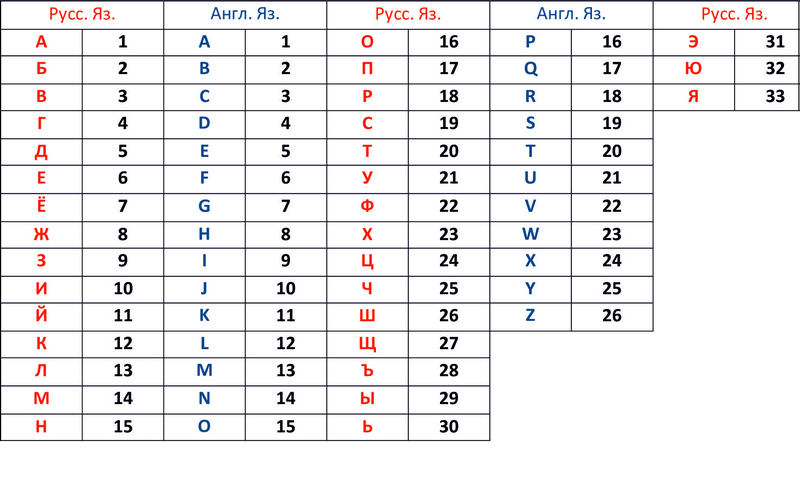
Рис. 2 Таблица соответствия букв и цифр алфавитов.
Теперь зашифруем словоК О С Т Е Р :
1) 1. Переведем буквы в цифры:К = 12, О = 16, С =19, Т = 20, Ё = 7, Р = 18
2) 2. Переведем цифры в символы согласно таблицы 1.
КП КТ КД ПЩ Ь КЛ
3) 3. Готово.
Этот пример показывает примитивный шифр. Рассмотрим похожие по сложности шрифты.
1. 1. Самым простым шифром является ШИФР С ЗАМЕНОЙ БУКВ ЦИФРАМИ. Каждой букве соответствует число по алфавитному порядку. А-1, B-2, C-3 и т.д.
Например слово «TOWN » можно записать как «20 15 23 14», но особой секретности и сложности в дешифровке это не вызовет.
2. Также можно зашифровывать сообщения с помощью ЦИФРОВОЙ ТАБЛИЦЫ. Её параметры могут быть какими угодно, главное, чтобы получатель и отправитель были в курсе. Пример цифровой таблицы.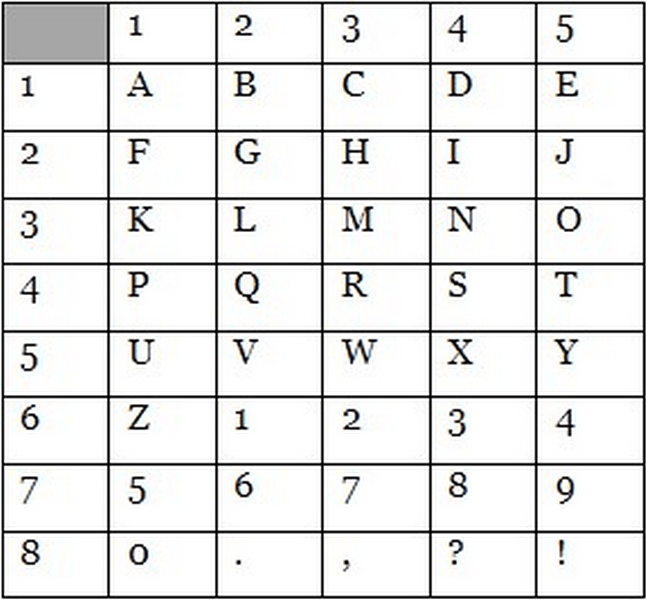
Рис. 3 Цифровая таблица. Первая цифра в шифре – столбец, вторая – строка или наоборот. Так слово «MIND» можно зашифровать как «33 24 34 14».
3. 3. КНИЖНЫЙ ШИФР
В таком шифре ключом является некая книга, имеющаяся и у отправителя и у получателя. В шифре обозначается страница книги и строка, первое слово которой и является разгадкой. Дешифровка невозможна, если книги у отправителя и корреспондента разных годов издания и выпуска. Книги обязательно должны быть идентичными.
4. 4. ШИФР ЦЕЗАРЯ
(шифр сдвига, сдвиг Цезаря)
Известный шифр. Сутью данного шифра является замена одной буквы другой, находящейся на некоторое постоянное число позиций левее или правее от неё в алфавите. Гай Юлий Цезарь использовал этот способ шифрования при переписке со своими генералами для защиты военных сообщений. Этот шифр довольно легко взламывается, поэтому используется редко. Сдвиг на 4. A = E, B= F, C=G, D=H и т.д.
Пример шифра Цезаря: зашифруем слово « DEDUCTION » .
Получаем: GHGXFWLRQ . (сдвиг на 3)
Еще пример:
Шифрование с использованием ключа К=3 . Буква «С» «сдвигается» на три буквы вперёд и становится буквой «Ф». Твёрдый знак, перемещённый на три буквы вперёд, становится буквой «Э», и так далее:
Исходный алфавит:А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
Шифрованный:Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В
Оригинальный текст:
Съешь же ещё этих мягких французских булок, да выпей чаю.
Шифрованный текст получается путём замены каждой буквы оригинального текста соответствующей буквой шифрованного алфавита:
Фэзыя йз зьи ахлш пвёнлш чугрщцкфнлш дцосн, жг еютзм ъгб.
5. ШИФР С КОДОВЫМ СЛОВОМ
Еще один простой способ как в шифровании, так и в расшифровке. Используется кодовое слово (любое слово без повторяющихся букв). Данное слово вставляется впереди алфавита и остальные буквы по порядку дописываются, исключая те, которые уже есть в кодовом слове. Пример: кодовое слово – NOTEPAD.
Исходный:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Замена:N O T E P A D B C F G H I J K L M Q R S U V W X Y Z
6. 6. ШИФР АТБАШ
Один из наиболее простых способов шифрования. Первая буква алфавита заменяется на последнюю, вторая – на предпоследнюю и т.д.
Пример: « SCIENCE » = HXRVMXV
7. 7. ШИФР ФРЕНСИСА БЭКОНА
Один из наиболее простых методов шифрования. Для шифрования используется алфавит шифра Бэкона: каждая буква слова заменяется группой из пяти букв «А» или «B» (двоичный код).
a AAAAA g AABBA m ABABB s BAAAB y BABBA
b AAAAB h AABBB n ABBAA t BAABA z BABBB
c AAABA i ABAAA o ABBAB u BAABB
d AAABB j BBBAA p ABBBA v BBBAB
e AABAA k ABAAB q ABBBB w BABAA
f AABAB l ABABA r BAAAA x BABAB
Сложность дешифрования заключается в определении шифра. Как только он определен, сообщение легко раскладывается по алфавиту.
Существует несколько способов кодирования.
Также можно зашифровать предложение с помощью двоичного кода. Определяются параметры (например, «А» - от A до L, «В» - от L до Z). Таким образом, BAABAAAAABAAAABABABB означает TheScience of Deduction ! Этот способ более сложен и утомителен, но намного надежнее алфавитного варианта.
8. 8. ШИФР БЛЕЗА ВИЖЕНЕРА.
Этот шифр использовался конфедератами во время Гражданской войны. Шифр состоит из 26 шифров Цезаря с различными значениями сдвига (26 букв лат.алфавита). Для зашифровывания может использоваться tabula recta (квадрат Виженера). Изначально выбирается слово-ключ и исходный текст. Слово ключ записывается циклически, пока не заполнит всю длину исходного текста. Далее по таблице буквы ключа и исходного текста пересекаются в таблице и образуют зашифрованный текст.

Рис. 4 Шифр Блеза Виженера
9. 9. ШИФР ЛЕСТЕРА ХИЛЛА
Основан на линейной алгебре. Был изобретен в 1929 году.
В таком шифре каждой букве соответствует число (A = 0, B =1 и т.д.). Блок из n-букв рассматривается как n-мерный вектор и умножается на (n х n) матрицу по mod 26. Матрица и является ключом шифра. Для возможности расшифровки она должна быть обратима в Z26n.
Для того, чтобы расшифровать сообщение, необходимо обратить зашифрованный текст обратно в вектор и умножить на обратную матрицу ключа. Для подробной информации – Википедия в помощь.
10. 10. ШИФР ТРИТЕМИУСА
Усовершенствованный шифр Цезаря. При расшифровке легче всего пользоваться формулой:
L= (m+k) modN , L-номер зашифрованной буквы в алфавите, m-порядковый номер буквы шифруемого текста в алфавите, k-число сдвига, N-количество букв в алфавите.
Является частным случаем аффинного шифра.
11. 11. МАСОНСКИЙ ШИФР


12. 12. ШИФР ГРОНСФЕЛЬДА
По своему содержанию этот шифр включает в себя шифр Цезаря и шифр Виженера, однако в шифре Гронсфельда используется числовой ключ. Зашифруем слово “THALAMUS”, используя в качестве ключа число 4123. Вписываем цифры числового ключа по порядку под каждой буквой слова. Цифра под буквой будет указывать на количество позиций, на которые нужно сдвинуть буквы. К примеру вместо Т получится Х и т.д.
T H A L A M U S
4 1 2 3 4 1 2 3
T U V W X Y Z
0 1 2 3 4
В итоге: THALAMUS = XICOENWV
13. 13. ПОРОСЯЧЬЯ ЛАТЫНЬ
Чаще используется как детская забава, особой трудности в дешифровке не вызывает. Обязательно употребление английского языка, латынь здесь ни при чем.
В словах, начинающихся с согласных букв, эти согласные перемещаются назад и добавляется “суффикс” ay. Пример: question = estionquay. Если же слово начинается с гласной, то к концу просто добавляется ay, way, yay или hay (пример: a dog = aay ogday).
В русском языке такой метод тоже используется. Называют его по-разному: “синий язык”, “солёный язык”, “белый язык”, “фиолетовый язык”. Таким образом, в Синем языке после слога, содержащего гласную, добавляется слог с этой же гласной, но с добавлением согласной “с” (т.к. язык синий). Пример:Информация поступает в ядра таламуса = Инсифорсомасацисияся поссотусупасаетсе в ядсяраса тасаласамусусаса.
Довольно увлекательный вариант.
14. 14. КВАДРАТ ПОЛИБИЯ
Подобие цифровой таблицы. Существует несколько методов использования квадрата Полибия. Пример квадрата Полибия: составляем таблицу 5х5 (6х6 в зависимости от количества букв в алфавите).

1 МЕТОД. Вместо каждой буквы в слове используется соответствующая ей буква снизу (A = F, B = G и т.д.). Пример: CIPHER - HOUNIW.
2 МЕТОД. Указываются соответствующие каждой букве цифры из таблицы. Первой пишется цифра по горизонтали, второй - по вертикали. (A = 11, B = 21…). Пример: CIPHER = 31 42 53 32 51 24
3 МЕТОД. Основываясь на предыдущий метод, запишем полученный код слитно. 314253325124. Делаем сдвиг влево на одну позицию. 142533251243. Снова разделяем код попарно.14 25 33 25 12 43. В итоге получаем шифр. Пары цифр соответствуют букве в таблице: QWNWFO.
Шифров великое множество, и вы так же можете придумать свой собственный шифр, однако изобрести стойкий шифр очень сложно, поскольку наука дешифровки с появлением компьютеров шагнула далеко вперед и любой любительский шифр будет взломан специалистами за очень короткое время.
Методы вскрытия одноалфавитных систем (расшифровка)
При своей простоте в реализации одноалфавитные системы шифрования легко уязвимы.
Определим количество различных систем в аффинной системе. Каждый ключ полностью определен парой целых чисел a и b, задающих отображение ax+b. Для а существует j(n) возможных значений, где j(n) - функция Эйлера, возвращающая количество взаимно простых чисел с n, и n значений для b, которые могут быть использованы независимо от a, за исключением тождественного отображения (a=1 b=0), которое мы рассматривать не будем.
Таким образом получается j(n)*n-1 возможных значений, что не так уж и много: при n=33 в качестве a могут быть 20 значений(1, 2, 4, 5, 7, 8, 10, 13, 14, 16, 17, 19, 20, 23, 25, 26, 28, 29, 31, 32), тогда общее число ключей равно 20*33-1=659. Перебор такого количества ключей не составит труда при использовании компьютера.
Но существуют методы упрощающие этот поиск и которые могут быть использованы при анализе более сложных шифров.
Частотный анализ
Одним из таких методов является частотный анализ. Распределение букв в криптотексте сравнивается с распределением букв в алфавите исходного сообщения. Буквы с наибольшей частотой в криптотексте заменяются на букву с наибольшей частотой из алфавита. Вероятность успешного вскрытия повышается с увеличением длины криптотекста.
Существуют множество различных таблиц о распределении букв в том или ином языке, но ни одна из них не содержит окончательной информации - даже порядок букв может отличаться в различных таблицах. Распределение букв очень сильно зависит от типа теста: проза, разговорный язык, технический язык и т.п. В методических указаниях к лабораторной работе приведены частотные характеристики для различных языков, из которых ясно, что буквы буквы I, N, S, E, A (И, Н, С, Е, А) появляются в высокочастотном классе каждого языка.
Простейшая защита против атак, основанных на подсчете частот, обеспечивается в системе омофонов (HOMOPHONES) - однозвучных подстановочных шифров, в которых один символ открытого текста отображается на несколько символов шифротекста, их число пропорционально частоте появления буквы. Шифруя букву исходного сообщения, мы выбираем случайно одну из ее замен. Следовательно простой подсчет частот ничего не дает криптоаналитику. Однако доступна информация о распределении пар и троек букв в различных естественных языках.